I know this is a skill issue on my part, but let me explain what I got tripped up on first, and then ask a dumb question about an Odin language design decision.
For wasm builds, you can’t have a single main() procedure - instead, you have to break things out into init(), step(), and shutdown(). So that’s what I did, and I added code in init() to set the context allocator to a tracking allocator (following the Odin book), like so:
init :: proc() {
when ODIN_DEBUG {
mem.tracking_allocator_init(&mem_tracker, context.allocator)
context.allocator = mem.tracking_allocator(&mem_tracker)
}
...
}
step :: proc() -> bool {
...
}
shutdown :: proc() {
...
when ODIN_DEBUG {
if len(mem_tracker.allocation_map) > 0 {
for _, entry in mem_tracker.allocation_map {
fmt.eprintf("%v leaked %v bytes\n", entry.location, entry.size)
}
}
mem.tracking_allocator_destroy(&mem_tracker)
}
}
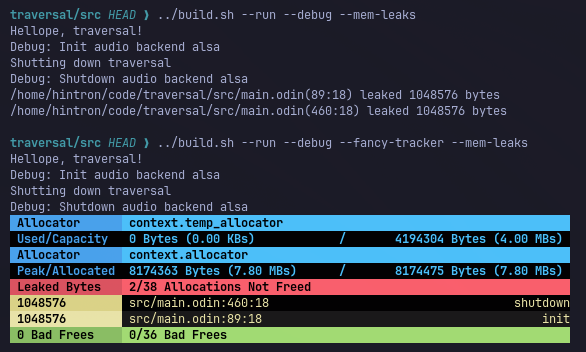
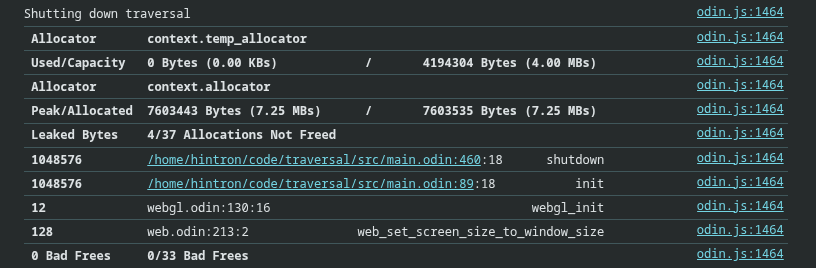
However, I was seeing memory leaks that I did not expect. Karl helpfully pointed out that I was setting up the tracking allocator wrong - that the context I was setting was actually just for the scope of the init() procedure. (See Issues · karl-zylinski/karl2d · GitHub)
As a noob to the language, I was assuming that I was setting the global context (and that’s what it feels like to me, coming from nearly any other language). I now understand, though, that when you are inside a procedure, context refers to the context passed into that procedure, and in the global scope, context is the global context.
So my language design question is this: Why shouldn’t context inside a procedure require an explicit procedure parameter? E.g. something like this:
init :: proc(ctx: contextT) {
when ODIN_DEBUG {
mem.tracking_allocator_init(&mem_tracker, ctx.allocator)
ctx.allocator = mem.tracking_allocator(&mem_tracker)
}
...
}
(I’m not sure what type ctx should be, but I’m guessing it would be type aliased to something)
Some advantages to this approach:
- Procedures now declare that they are modifying the context in the procedure signature, so it’s easier to see when context shenanigans are going on
- It is easier for newcomers to the language, since
contextnow would not look like you are setting a global variable - You can set the global context from within a procedure instead of doing the thing where you have to save it to a variable first.
And since setting the global context from within a procedure is rare, maybe it could be gated behind some kind of #directive so that newcomers don’t unwittingly override the global context when they forget to add the procedure parameter.
Those are just my initial thoughts after hitting this issue for the first time. I’m no language expert, so I am happy to hear why this wouldn’t be a good idea, or if this has some merit. Thanks