I designed a memory management syntax that is easy almost like a GC lang, drawing on the principles of C++ RAII and Rust lifetimes. The reason memory management is so complex in C++ and Rust is their lack of a syntax for defining module trees. If so, RAII and lifetimes could have been very simple, no need for borrow checker entirely. Depending on the specific language, the “module tree” could be a package tree, file tree, namespace tree, or class tree—essentially any tree representing scopes. The class syntax in OOP was originally designed to define module trees, but it suffers from significant flaws; I have explained the root causes of these syntactic defects in a YouTube video and proposed a new syntax design to resolve them.
In languages that do not support this syntax, it can also be implemented indirectly using mechanisms such as defer and namespaces, as a design pattern. The underlying principles are the same.
Let me first demonstrate the programming process when using module trees for memory reclamation.
When designing a program, programmers typically visualize its module architecture. Consider the following architecture for an FPS game featuring two modes: 1v1 and 5v5.
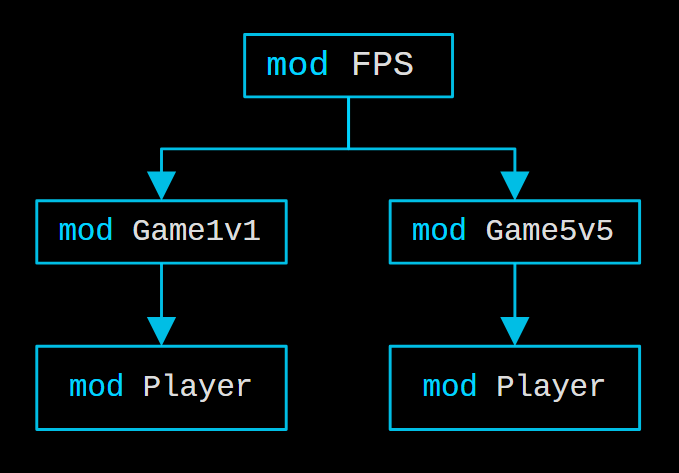
Write the program directly based on the module architecture diagram in your mind. See below.
mod FPS(Game1v1, Game5v5) {}
mod Game1v1(Player) {
run fn end() {}
}
mod Game5v5(Player) {
run fn end() {}
}
mod Player {
fn fire() {
this..super.end()
}
}
The mod elements in the code correspond one-to-one with the modules in the module architecture diagram.
If you need to reclaim the memory used by a game session once it ends, simply define a destructor for that module and link it to an external trigger event. In this example, the game ends in victory when the player fires and defeats all enemis.
Then the memory management is done.
Here, run is the keyword used to define the destructor; the difference from a standard destructor is that the programmer does not need to write the actual cleanup logic. The choice of the keyword run holds no special significance—you could just as easily use destruction or free_this_scope_all.
Let’s explain the underlying principles.
Programs can be categorized into two types: procedural programs and standby programs.
Procedural programs are characterized by continuous execution; once execution finishes, all memory allocated during the process can be reclaimed, with interaction with the outside world limited to input parameters and output return values. This is similar to how the operating system reclaims memory allocated by the main function after it terminates. Programmers do not need to worry about memory reclamation for procedural programs, as all newly allocated memory is automatically freed when the function finishes. You can think of a “process” simply as a function—while they aren’t exactly identical, this is a useful simplification for now.
Standby programs are characterized by their ability to remain in memory without executing any instructions. Their reclamation is always triggered externally; the program itself does not decide when to free the memory—it might be triggered in ten seconds or not for a million years. Consequently, the reclamation process is always tied to an external trigger event. Standby programs typically store only shared state, pool data, or pool-like data.
By structuring the standby program components according to the program’s logical architecture tree, you ensure that reclaiming a parent node forces the reclamation of all its child nodes. Thus, you only need to focus on the specific nodes that require collective reclamation.
This tree effectively represents your program’s resident memory scope tree, logical architecture tree, module architecture tree, and logical memory model. This structure makes the program easiest to read and write, as the code corresponds one-to-one with the logical architecture diagram, allowing for seamless conversion between the two using tools. The convention of this syntax dictates that a variable’s lifetime is tied to the scope in which it is declared—a relationship that is unique and immutable; reclaiming a parent scope forces the reclamation of its child scopes. Modules, packages, files, namespaces, and functions all constitute scopes. Semantically, every memory variable is associated with exactly one designated parent: either a module scope (where reclamation is triggered externally) or a function scope (where reclamation occurs automatically upon the function’s termination).
The syntax prohibits a scenario where a child node remains in memory after its parent node has been reclaimed. Semantically, this is equivalent to the situation where “memory remains unreclaimed yet the pointer is lost”—except that, in this case, what is lost is the semantic attachment point, akin to a handle.
There are two other less commonly used keywords: up and defer.
The up keyword is used to mark a function in order to optimize the timing of memory reclamation within the function’s scope.
fn outer(){
inner()
}
up fn inner(){
a []int = [1,2,3]
}
Functions marked with the up keyword are not reclaimed immediately after the inner function finishes; instead, they are reclaimed only when the outer function concludes. Note that although variable a is not reclaimed until after outer finishes, it cannot be accessed within outer. The up keyword is used solely to optimize the timing of resource reclamation; it does not alter the access scope.
The defer keyword is used to reclaim resources requested from external entities, such as database connections or file handles. This is because the memory management mechanism can only automatically reclaim memory belonging to the local program; it cannot reclaim memory held by remote programs (such as a remote database). Reclaiming memory held by a remote program generally requires sending a message to that program, instructing it to perform the reclamation.
fn user(){
db_conn := libDb_newConn()
// no need to write any code of releasing db_conn
}
fn libDb_newConn(){
a := db.sendMessageToDb('Connect with me')
defer a {
db.sendMessageToDb('disconnect with me')
}
// defer must bind one variable
return a
}
Programmers do not need to manually manage the release of db_conn; they simply need to properly define its scope, and the defer action will execute automatically once the variable goes out of scope.